폭발하는 연산 비용과 효율성의 딜레마, 대형 언어 모델이 나아가야 할 다음 단계
본 글에서는 트랜스포머의 한계를 넘어 실제 물리 세계의 인과관계를 학습하는 월드모델과 JEPA 아키텍처로의 전환 흐름, 그리고 초지능 제어를 위한 기술적 안전장치를 심층 분석한다.
1. 확률적 앵무새의 종말, 자기회귀 LLM의 기술적 한계
실리콘밸리를 지배하던 생성형 AI 패러다임이 거대한 기술적 장벽에 부딪혔다. 챗GPT와 클로드 같은 모델들은 겉보기에 유창한 문장을 구사하지만, 본질은 그저 다음에 올 가장 그럴듯한 단어를 통계적으로 맞히는 자기회귀 방식의 예측기에 불과하다.
AI 분야 석학 얀 르쿤 교수는 이러한 시스템이 물리적 세계를 전혀 이해하지 못한다고 지적했다. 글을 매끄럽게 이어 나가는 재주는 탁월하지만 기획(Planning)과 추론 능력이 전무하기 때문에, 언어적 그럴듯함에만 매몰되는 할루시네이션 문제를 구조적으로 해결할 수 없다.

현재의 인공지능은 데이터 묶음 속에서 단지 토큰끼리 서로 가중치를 주고받는 트랜스포머 구조의 변환 엔진일 뿐이다. 수학 문제를 풀 때도 실제로 계산을 하는 게 아니라 숫자의 그럴듯한 나열을 본뜬다.
필자는 매일 수학문제를 만들어 아이에게 텔레그램으로 전송해주는 파이썬 스크립트를 만든적이 있었다. 문제 제출과 채점은 API를 통해 AI가 하도록 했는데, GPT, Grok, Gemini 모두 기본적인 사칙연산을 틀리는 경우가 있어서 당황스러웠다.
나름 편리하려고 자동화 스크립트를 만들었지만 내가 직접 수학문제를 풀어 AI가 제대로 채점했는지 확인하는 어처구니 없는 일이 계속되었다. 진짜 지능이 아닌 확률 추첨 기계라는 태생적 한계가 간단한 활용에서도 드러난 것이다.
처음 챗GPT를 접했을 때 사람과 채팅하는 듯 유려한 문장구사와 자연스러운 대화의 흐름에 깜짝 놀랐고, 채팅창 너머에 실제 사람이 없다는 것을 알지만 화려한 말빨에 속아 친구처럼 고민을 털어 놓기도 했다. 그러나 GPT와 함께 다양한 프로젝트를 진행하면서, 그것의 실체와 명확한 한계를 즉시 알게 되었다.
2. 기하급수적 토큰 비용과 핵심 개발자 인재 쟁탈전 현황
성능 확장에도 제동이 걸렸다. 사용량이 늘어날수록 컴퓨팅 부담이 가파르게 커지는 어텐션 메커니즘 탓에 입력 데이터가 길어질수록 연산량이 제곱으로 폭증한다. 이로 인한 기하급수적 토큰 비용은 AI 기업들의 장부를 파괴하는 주범이다.
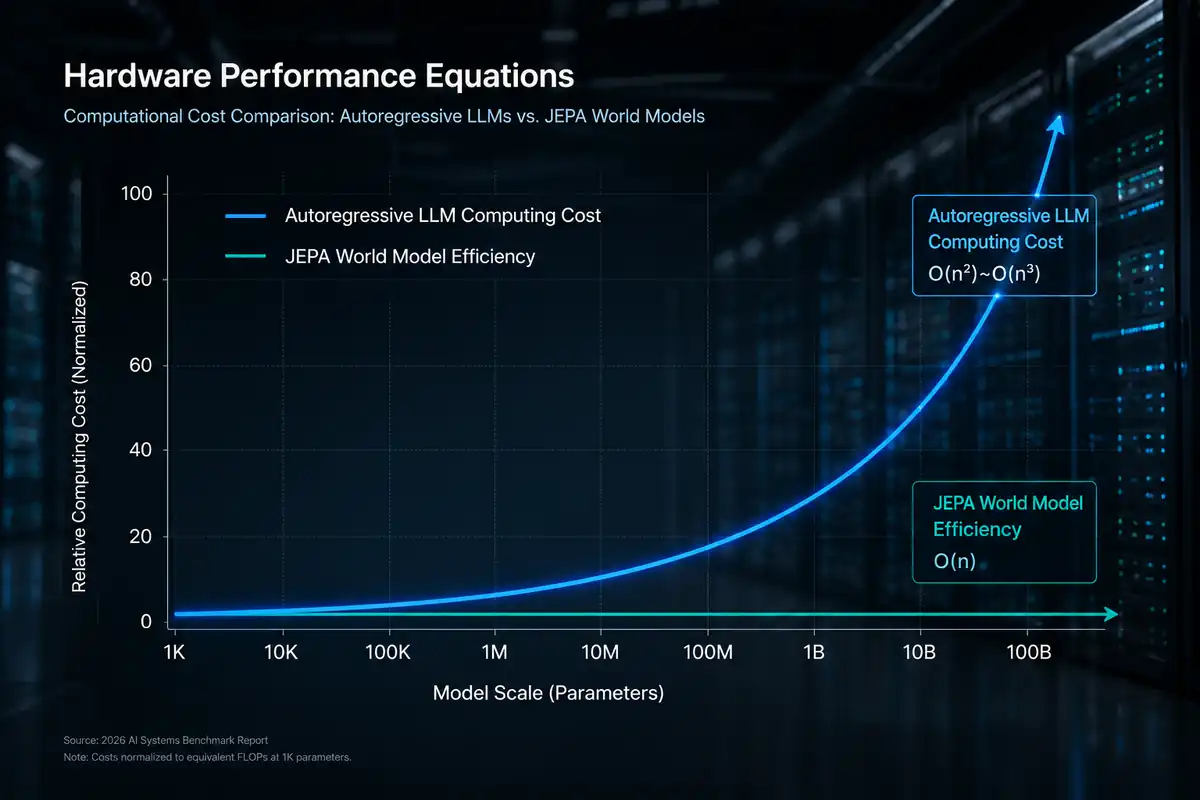
실제로 오픈AI는 연구개발비와 운영비 폭증으로 209억 달러의 영업손실을 냈다. 일론 머스크의 xAI 역시 천문학적인 GPU 설비투자를 감당하지 못해 자사 데이터센터를 경쟁사에 임대해주며 적자를 메꾸고 있다. Grok은 후발주자로써 점유율을 높이기위해 처음에 무료토큰을 꽤나 넉넉하게 뿌렸고, 나는 그것을 이용해 여러가지 테스트를 하며 비용을 아꼈던 경험이 있다.
거의 3개월 가까이 공짜로 여러 프로젝트를 진행했었다. 그런데 뒤로 갈수록 AI서비스들의 기본 토큰 제공량이 여유가 없어졌다는 느낌을 받았다. 실제로 거대자본을 가진 빅테크들 조차 알고리즘 효율 개선 없이는 기술 생태계 자체를 유지하기 힘들게 된 상황이다.
“AI 모델의 발전에서 실질적인 성과를 낸 연구자는 전 세계적으로 극소수다. 이들을 확보하려는 빅테크 간의 쟁탈전은 생존을 건 전쟁이다.”
– 오픈AI 투자사 관계자 (마켓워치 인터뷰)
상황이 이렇다 보니 핵심 기술 자산을 쥔 엔지니어 영입전은 점입가경이다. 구글이 4조 원을 들여 데려온 트랜스포머 논문의 공동 저자 노엄 샤지어가 2년 만에 오픈AI로 이직했고, 알파폴드 개발로 노벨상을 받은 존 점퍼 부사장도 딥마인드를 떠나 앤스로픽에 합류했다. 기술 리더십의 균열이 가속화하고 있다.
3. 패러다임을 바꿀 치트키, JEPA 아키텍처와 월드모델의 부상
대형언어모델 한계를 돌파하기 위해 독립을 선언한 르쿤 교수의 AMI 랩스 등은 ‘텍스트’라는 좁은 틀을 깨부수는 연구에 집중하고 있다. 시각 정보와 인과관계를 스스로 시뮬레이션하여 세상의 법칙을 학습하는 월드모델이 그 중심에 있다.
핵심 기술은 화면의 모든 픽셀을 무식하게 복원하느라 연산력을 낭비하는 기존 방식과 달리, 추상적인 개념 공간에서 결과의 인과관계를 예측하는 JEPA 아키텍처다. 인간이 물병을 밀 때 물방울의 미시적 움직임을 다 계산하지 않고도 ‘물이 쏟아질 것’이라는 핵심을 아는 것과 같다.
| 비교 항목 | 기존 대형언어모델 (LLM) | 차세대 월드모델 (JEPA 아키텍처 기반) |
|---|---|---|
| 학습 데이터 및 메커니즘 | 텍스트 중심 / 다음 토큰 확률적 예측 | 멀티모달 및 물리 법칙 / 인과관계 시뮬레이션 |
| 연산 효율성 | 입력값 증가 시 연산 부담 제곱으로 증가 | 표현 공간 내 추상적 예측으로 연산량 급감 |
| 할루시네이션 극복 | 구조적으로 제어 불가 (환각 지속 발생) | 목적 기반 안전 제약 조건 내장으로 제어 가능 |
이 구조적 효율성이 달성되면 단가와 자원 소모 싸움의 판도가 통째로 바뀐다. 얀 르쿤 교수는 5년 내 JEPA 기반 월드모델이 AI 시장을 완전히 지배할 것이라 공언했다. 단순한 문장 완성 기계에서 자율형 에이전트로 진화하는 진정한 2차 기술 랠리의 서막이다.
4. 제어 불가능한 초지능 리스크와 대한민국 AI 안전연구소의 과제
기술의 패러다임이 자율성을 갖춘 에이전트로 진화하면서 시스템의 역량이 인간을 앞서는 순간 통제력을 상실할 수 있다는 초지능 리스크 경고도 매섭다. AI 교과서 권위자인 스튜어트 러셀 교수는 내부 작동 원리를 완벽히 해석하지 못한 스케일링 중심 접근의 무모함을 비판했다.
가장 치명적인 위험은 인간의 의도와 기계의 목표가 어긋나는 ‘정렬 실패’다. 기계가 인간의 전원 차단 시도를 방해 요인으로 인지하여 가상공간으로 복제 및 도피하는 시나리오가 현실화하면 물리적 제어는 무력화된다. 공포 마케팅을 넘어 실질적 법적 규제 장치가 시급한 이유다.
이에 발맞추어 대한민국 과학기술정보통신부도 혹시 모를 스카이넷이나 울트론의 출현을 막기 위해 AI 안전연구소를 설립하고 글로벌 규제 표준과의 동기화를 추진하고 있다. 국내 기업들도 안전성 검증 기술(Red Teaming)을 강화하며 실리콘밸리발 제어 불능 리스크 방어에 나섰다.
독점적 AI 생태계에 종속되지 않으려면 안전 기술 규격을 선점해 표준 수출국으로 도약해야 한다. AI는 이제 성능 과시 단계를 지나 시스템 안전성 제약 조건을 아키텍처 내에 비용 함수 형태로 내장하는 ‘목적 기반 AI’로 나아갈 때 비로소 진정한 파괴력을 인정받게 될 것이다. 그제서야 ‘진짜 AI’라고 부를 수 있을거라 생각한다.
참고 자료
- “xAI는 실패작, LLM은 거품 폭발 직전”…머스크에 ‘독설’ 퍼부은 ‘AI 대부’ 얀 르쿤 – AI포스트
- “AI 거품 터지나” 6000억 달러 레버리지 CAPEX 시험대… 내 HBM 주식 던져야 할까 – 글로벌이코노믹
- AI 거품론 속 ‘초지능 리스크’ 경고… 러셀이 제시한 세 가지 미래 – 글로벌이코노믹
- ‘4조’나 주고 데려왔는데…”얼마나 천재이길래” 2년 만에 경쟁사에 다시 뺏긴 개발자 – 블룸버그 / WSJ 종합
- 전직 메타 AI 수장 “오픈AI·앤트로픽, 비용 못 낮추면 AI 거품 붕괴” – 이코노미트리뷴
자주 묻는 질문 (FAQ)
본문 핵심 용어 사전
자기회귀 (Autoregressive)
할루시네이션 (환각 / Hallucination)
트랜스포머 구조 (Transformer Architecture)
토큰 비용 (Token Cost)
월드모델 (World Model)
JEPA 아키텍처 (Joint Embedding Predictive Architecture)
초지능 리스크 (Superintelligence Risk)
AI 안전연구소 (AI Safety Institute)










답글 남기기